Der Code 39 ist eine ältere Codeart, die pro einem Codewort nur die Ziffern 0 bis 9, die Großbuchstaben A bis Z und die Zeichen "space $ % + - . /" kodieren kann.
(space steht für das Leerzeichen bzw. Leerschritt)
Es gibt den erweiterten ASCII Modus. Von der Anwendung ist aber abzuraten, da pro Zeichen 2 Codewörter notwendig sind.
Ein Zeichen wird immer in 5 Strichen und 4 Lücken kodiert. Zwischen den Zeichen ist immer eine Trennlücke (gelb in den Bildern hervorgehoben) enthalten, damit der letzte Strich eines Zeichens nicht direkt, ohne Lücke, auf den ersten Strich des folgenden Zeichens anschließt. Bei anderen Codearten ist das geschickter gelöst. Ein Zeichen endet z.B. mit einer Lücke und beginnt mit einem Strich. Eine Trennlücke wie dies beim Code 39 zwingend ist wird dann nicht mehr benötigt.
Anhand der folgenden neun, vollständigen Codes wird der kompette Zeichensatz des Code 39 gezeigt (das zehnte Codebild zeigt einen Sonderfall).
Die blauen Striche mit den dazwischenliegenden weißen Lücken sind jeweils das Start- und Stoppzeichen. Die Datenzeichen bestehen aus vier Lücken die rot dargestellt sind und 5 dunklen Strichen die schwarz dargestellt werden. Die gelben Striche sind die Trennlücken (Gap oder intercharacter gap), die benötigt werden weil die Datenzeichen mit einem Strich beginnen und enden. Die Trennlücken haben normalerweise die Breite von einem Modul. Erlaubt sind allerdings bis zu 5,3 Module. Diese Breitenvariation der Trennlücke wird in der Praxis so gut wie nie benutzt. Die große Variation der Trennlücke ist in den historischen Drucksystemen begründet, die den Code mit einer speziellen Schreibmaschine erzeugt haben.
Unter jedem Code ist eine Tabelle eingefügt die das Bitmuster der Zeichen zeigt. Eine 1 steht dabei für ein breites Element und eine 0 für ein schmales Element. Das Bitmuster wird in der Abfolge der Strich und Lücken gezeigt. Das erste Element ist immer ein Strich. (B - Balken, L = Lücke)

| Zeichen | B | L | B | L | B | L | B | L | B |
|---|---|---|---|---|---|---|---|---|---|
| 1 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 1 |
| 2 | 0 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 1 |
| 3 | 1 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 |
| 4 | 0 | 0 | 0 | 1 | 1 | 0 | 0 | 0 | 1 |
| 5 | 1 | 0 | 0 | 1 | 1 | 0 | 0 | 0 | 0 |

| Zeichen | B | L | B | L | B | L | B | L | B |
|---|---|---|---|---|---|---|---|---|---|
| 6 | 0 | 0 | 1 | 1 | 1 | 0 | 0 | 0 | 0 |
| 7 | 0 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 1 |
| 8 | 1 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 0 |
| 9 | 0 | 0 | 1 | 1 | 0 | 0 | 1 | 0 | 0 |
| 0 | 0 | 0 | 0 | 1 | 1 | 0 | 1 | 0 | 0 |

| Zeichen | B | L | B | L | B | L | B | L | B |
|---|---|---|---|---|---|---|---|---|---|
| A | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 1 |
| B | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 1 |
| C | 1 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 0 |
| D | 0 | 0 | 0 | 0 | 1 | 1 | 0 | 0 | 1 |
| E | 1 | 0 | 0 | 0 | 1 | 1 | 0 | 0 | 0 |

| Zeichen | B | L | B | L | B | L | B | L | B |
|---|---|---|---|---|---|---|---|---|---|
| F | 0 | 0 | 1 | 0 | 1 | 1 | 0 | 0 | 0 |
| G | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 0 | 1 |
| H | 1 | 0 | 0 | 0 | 0 | 1 | 1 | 0 | 0 |
| I | 0 | 0 | 1 | 0 | 0 | 1 | 1 | 0 | 0 |
| J | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 0 | 0 |

| Zeichen | B | L | B | L | B | L | B | L | B |
|---|---|---|---|---|---|---|---|---|---|
| K | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 |
| L | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 1 | 1 |
| M | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 1 | 0 |
| N | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 1 | 1 |
| O | 1 | 0 | 0 | 0 | 1 | 0 | 0 | 1 | 0 |

| Zeichen | B | L | B | L | B | L | B | L | B |
|---|---|---|---|---|---|---|---|---|---|
| P | 0 | 0 | 1 | 0 | 1 | 0 | 0 | 1 | 0 |
| Q | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 1 |
| R | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 0 |
| S | 0 | 0 | 1 | 0 | 0 | 0 | 1 | 1 | 0 |
| T | 0 | 0 | 0 | 0 | 1 | 0 | 1 | 1 | 0 |

| Zeichen | B | L | B | L | B | L | B | L | B |
|---|---|---|---|---|---|---|---|---|---|
| U | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 |
| V | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 1 |
| W | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 |
| X | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 1 |
| Y | 1 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 0 |
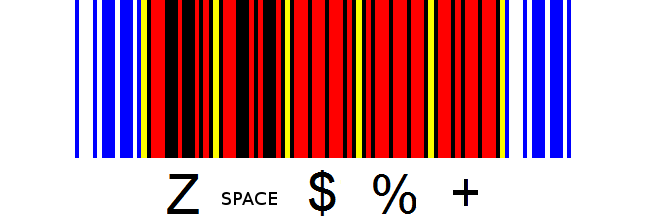
| Zeichen | B | L | B | L | B | L | B | L | B |
|---|---|---|---|---|---|---|---|---|---|
| Z | 0 | 1 | 1 | 0 | 1 | 0 | 0 | 0 | 0 |
| SPACE | 0 | 1 | 1 | 0 | 0 | 0 | 1 | 0 | 0 |
| $ | 0 | 1 | 0 | 1 | 0 | 1 | 0 | 0 | 0 |
| % | 0 | 0 | 0 | 1 | 0 | 1 | 0 | 1 | 0 |
| + | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 1 | 0 |
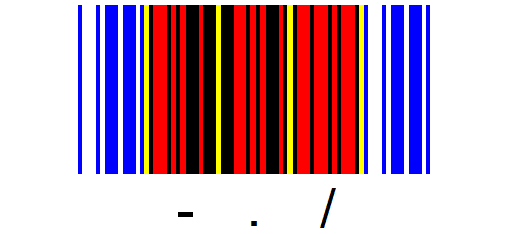
| Zeichen | B | L | B | L | B | L | B | L | B |
|---|---|---|---|---|---|---|---|---|---|
| - | 0 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 1 |
| . (Punkt) | 1 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 0 |
| / | 0 | 1 | 0 | 1 | 0 | 0 | 0 | 1 | 0 |
Das folgende Beispiel zeigt einen Code der dreimal das Zeichen "*" kodiert. Dieses Zeichen wird als Start und Stoppzzeichen benutzt. Innerhalb des Code darf das Zeichen nicht benutzt werden, weil der Scanner dann entweder an der falschen STelle anfängt zu dekodieren oder an der falschen Stelle aufhört. In einer geschlossenen Anwendung in der die Scannerauswahl unter Kontrolle ist könnte man Scanner aussuchen die so programmiert sind, dass das Start- bzw. Stoppzeichen im Code toleriert wird. in einer offenen Anwendung ist der Scannertyp nicht bekannt und daher ist ein Start/Stoppzeichen im Code verboten.

| Zeichen | B | L | B | L | B | L | B | L | B |
|---|---|---|---|---|---|---|---|---|---|
| * (Start und Stopp) | 0 | 1 | 0 | 0 | 1 | 0 | 1 | 0 | 0 |
Die gelben Striche sind die Trennlücken (engl Intercharacter Gap abgekürzt Ig).
Alle Beispiele sind als vollständige Codes gezeigt. Es handelt sich aber nur um Prinzipbilder, die lesbar sein können aber nicht müssen.
Der Code 39 gehört zu Kategorie der Codearten mit 2 Strichbreiten. Der breite Strich darf zwischen 2 bis 3 mal breiter sein als der dünne Strich. Das Verhältnis zwischen dünnen und breiten Strich wird als Ratio bezeichnet.
Links und rechts des Strichcodes muss ein heller Bereich freibleiben. Man bezeichnet diesen hellen Bereich als Ruhezone oder Hellfeld. Die Mindestbreite des Hellfeldes ist eine relative Angabe in Bezug auf die Idealbreite eines dünnen Striches (Modulbreite). Mindestens 10 x der Breite des schmalen Striches muss links wie auch rechts des Codes freibleiben.
Der Code kann eine Prüfziffer beinhalten. Diese wird üblicherweise in dem Modulo 43 Verfahren berechnet. Wenn nur Ziffern kodiert werden dann wird auch Modulo 10 verwendent.
Der Code ist in einer ISO/IEC Norm normiert: ISO/IEC 16388
Die Anfälligkeit gegen zu kurzes Lesen ist deutlich geringer als bei dem 2/5i Code. Dies begründet sich dadurch, dass das Start- und Stoppzeichen genauso aufgebaut ist wie ein Datenzeichen und keine Teilmenge eines Datenzeichens ist. Die Muster des Start- und Stoppzeichens (Blaue Striche, gelbe Lücken in den Bildern) wiederholen sich oft mehrfach in einem Code. Man sollte daher einen waagerechten Strich über und unter dem Code drucken der jeweils deutlich breiter ist als ein breiter Strich im Code. Des weiteren sollte der Scanner nur die Länge des Codes akzeptieren die vorgesehen ist.
Die Prüfziffer ist auch mit Modulo 43 nur ein geringer Schutz gegen das Erkennen von fehlerhaften Lesungen.
Die größte Schwäche des Code 39 ist sein immenser Platzbedarf. Man stößt daher bei geringfügig erhöhten Datenmengen sehr schnell an Grenzen.
Die Codeversion Code 39 Full ASCII erlaubt die Kodierung von Kleinbuchstaben. Dazu wird immer ein Zeichenpärchen aus z.B. $ und einem Großbuchstaben benutzt. Diese Kombination wird vom Scanner in ein Zeichen gewandelt. Der Scanner muss auf auf Code39 Full ASCII eingestellt sein. Der ohnehin schon sehr große Code wird noch einmal doppelt so groß. Die Code 39 Full ASCII Version sollte daher vermieden werden. Der Code 128 kodiert den vollen ASCII Zeichensatz viel effektiver.