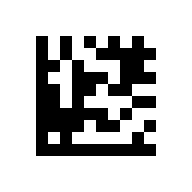Strichcodes und Matrixcodes kodieren Zeichen mit unterschiedlichen Darstellungen. Diese stimmen mit der Darstellung in einem Computer nicht überein.
Zeichensätze eines Computers
Die Anzeige von Buchstaben, Zahlen wie auch osteuropäische, asiatische Zeichen erfordert die Definition wie diese Computergerecht dargestellt werden. Die Basis ist der einfache ASCII Zeichensatz, der in der Norm ISO/IEC 646 beschrieben ist. Erweiterte Zeichen werden in der Norm ISO/IEC 10646 wie auch in der Normenreihe ISO 8859-x beschrieben.
Der einfache ASCII Zeichensatz ist wie folgt definiert:
ASCII-Zeichentabelle, hexadezimale Nummerierung | ||||||||||||||||
…0 | …1 | …2 | …3 | …4 | …5 | …6 | …7 | …8 | …9 | …A | …B | …C | …D | …E | …F | |
0… | ||||||||||||||||
1… | DC2 | DC4 | GS | |||||||||||||
2… | ||||||||||||||||
3… | ||||||||||||||||
4… | ||||||||||||||||
5… | ||||||||||||||||
6… | ||||||||||||||||
7… | ||||||||||||||||
Quelle : Wikipedia
Die Tabelle zeigt den Basiszeichensatz mit 128 verschiedenen Zeichen. Die ersten beiden Zeilen sind Steuerzeichen wie z.B. der Zeilenumbruch
Zeichensätze in Strich- und Matrixcodes
Strich- und Matrixcodes (optische Codes) benutzen auch Zeichensätze. Diese unterscheiden sich jedoch vom ASCII Zeichensatz und den genannten Normen. Das hat zur Folge, dass zwischen den in optischen Codes benutzen Zeichen und den auf Computern benutzen Zeichensätzen übersetzt werden muss. Dies muss immer in zwei Richtungen vorgenommen werden. Die eine Richtung ist die vom Computer zum Drucker und darin die korrekte Aufbereitung/Umsetzung der zu kodierenden Zeichen in den Zeichensatz des optischen Codes. Beim Lesen des Codes wird umgekehrt vorgegangen. Der Scanner muss die Zeichen, welche kodiert sind, analysieren und wieder passend für den Computer zurück übersetzen.
Bei einem Data Matrix Code als Beispiel sind die Zeichen wie folgt definiert:
| Codeword | Data or function |
| 1 - 128 | ASCII data (ASCII value + 1) |
| 129 | Pad (see chapter 5.2.4.3) |
| 130 - 229 | 2-digit data 00 - 99 (Numeric Value + 130) |
| 230 | Latch to C40 encodation |
| 231 | Latch to Base 256 encodation |
| 232 | FNC1 |
| 233 | Structured Append |
| 234 | Reader Programming |
| 235 | Upper Shift (shift to Extended ASCII) |
| 236 | 05 Macro (ISO/IEC 15434) |
| 237 | 06 Macro (ISO/IEC 15434) |
| 238 | Latch to ANSI X12 encodation |
| 239 | Latch to Text encodation |
| 240 | Latch to EDIFACT encodation |
| 241 | ECI Character |
| 242 - 255 | Not to be used in ASCII encodation |
Der Unterschied zum obigen ASCII Zeichensatz ist leicht erkennbar.
Mit dieser Tabelle allein kommt man aber noch nicht weiter, da es keine 1:1 Zuordnung gibt. In der ASCII Kodierung werden die Data Matrix Codeworte von 1 bis 128 benutzt. Der ASCII Werte (s. ASCII Tabelle) ist immer der Wert des Codewortes – 1. Wenn die Digit-Darstellung benutzt wird, werden die Codewörter von 130 bis 229 benutzt. 130 wird in dem Fall 2 ASCII Zeichen zugeordnet - nämlich zweimal die Ziffer 0. Damit wird im Code bei reiner Ziffernkodierung der Platz effizienter ausgenutzt (4-bit pro Zeichen anstelle von 8 bit bei Nutzung der Codeworte von 1 bis 128).
Diese Umsetzung ist aber nur die einfache Version. Zusätzlich gibt die Umschaltungen zu C40, ANSI X12, Text, EDIFACT und ECI (enhanced channel interpretation für kyrillisch, Arabisch, Kanji, Katakana usw.). Jede dieser Variationen hat eine andere Darstellung der Zeichen in Relation zu den benutzen Codewörtern im optischen Code. Man kann sogar eine rein binäre Kodierung verwenden, indem man die Methode Base 256 benutzt. In dem Fall muss in der Anwendung definiert werden, was die kodierten Daten bedeuten.
Andere optische Codes benutzen ähnliche Umsetzungen. Alle sind aber im Detail etwas verschieden. D.h. Scanner und Drucker müssen für jede Codeart die korrekte Übersetzung kennen und ausführen. Für den Anwender bleibt aufgrund dieser impliziten Übersetzungen der Effekt unsichtbar.
Nutzung eines Messgerätes zur Codeprüfung (Verifier)
Der Verifier muss - ebenso wie der Scanner - diese Übersetzung ebenfalls beherrschen. Im Gegensatz zu einem Scanner, der nur das übersetzte Ergebnis liefert, muss der Verifier aber die originale Darstellung im Code kennen, anzeigen und ggf. bewerten wie auch die Übersetzung.
Die Übersetzung wird mit Hilfe einer Tabelle visualisiert (Beispiel aus einem Data Matrix Code)

Die Tabelle unterteilt sich in dem Fall in 5 Hauptzeilen mit je zwei Zeilen pro Hauptzeile. Der obere Bereich der Hauptzeile zeigt die originalen Codewörter an, welche tatsächlich im Code vorhanden sind. Darunter werden die Bedeutungen der Zeichen angezeigt. Die Tabelle zeigt die Rohdaten an.
Die Rohdaten zeigen auch an welchen Stellen z.B. die Kodiermethoden C40, ASCII oder DIGIT benutzt werden.Die ASCII Kodierung benutzt feste Codewörter wie auch die Digit Kodierung. Daher benötigen diese Methoden keine Umschaltzeichen. Die anderen Methoden werden per Latch zeichen initiiert. Die Abfolge der Zeichensätze wird nach Normvorschrift so ausgeführt, dass im Code die geringstmögliche Anzahl von Codewörtern verbraucht werden.
Ein Scanner dagegen reduziert die Daten auf das, was für die Verarbeitung erforderlich ist:

Dies wird im REA Verifier als Decoder Ergebnis angezeigt. In einigen Fällen gibt es zwischen der Klartextdarstellung auf einem gedruckten Etikett (als eines von vielen Beispielen) und den Daten die der Decoder liefert einen Unterschied. Aus diesem Grund gibt es im REA Verifier auch noch die Klartextdarstellung als Anzeige.

Häufig tauchen Fragen bezüglich des FNC1 Zeichens auf. Aus der Data Matrix Codewort Tabelle ist ersichtlich, dass im Code zur Darstellung des FNC1 Zeichens das Codewort mit der Nummer 232 benutzt wird. Wenn in den Zeichensätzen des Rechners (ISO/IEC 646, 10646, ISO 8859-x) nach FNC1 gesucht wird dann wird dieses Zeichen dort nicht gefunden, weil es dort nicht existiert.
In der Codeworttabelle ist ersichtlich, dass das FNC1 Zeichen mit dem Wert 232 zweimal erscheint. Im Decoder Ergebnis ist es verschwunden. Dies muss so sein, weil wie ausgeführt das FNC1 Zeichen nur im Code - aber nicht in den Computerzeichensätzen definiert ist daher dort nicht darstellbar ist.
.
Das erste FNC1 Zeichen wird in die ASCII Zeichenfolge „]d2“ übersetzt. Dazu muss aber der Scanner so konfiguriert sein, dass der sogenannte Symbology Identifier auch übertragen wird. Wenn das nicht der Fall ist, wird das erste FNC1 Zeichen einfach verschluckt. Alle FNC1 Zeichen, welche an anderer Stelle erscheinen, werden anders behandelt. Dies ist in der Codeworttabelle in der Hauptzeile 3 ersichtlich. Dort erscheint „GS“ als Übersetzung. Das ist das ASCII-Zeichen mit dem Wert „29“ und der Bedeutung „Group Separator“. Es handelt sich um ein nicht darstellbares Zeichen (also keines dem ein sichtbares Zeichen oder Buchstabe zugeordnet ist). Die Funktion ist ein Steuerzeichen. In diesem Fall die Information, dass ein Datenfeld zu Ende ist.
Im Falle des „GS“-Zeichens besteht auch die Möglichkeit, es direkt zu kodieren.
Das sieht dann in der Codewortdarstellung wie folgt aus:

Im Decoderergebnis ist dieser Unterschied nicht mehr nachvollziehbar:

Da die Notwendigkeit der Übersetzung zwischen den Code- und Computerzeichensätzen vielen Anwendern nicht klar ist wird versucht das FNC1 Zeichen mit dem Wert 232 als ASCII Zeichen zu kodieren. Das führt zwangsweise zu falschen Ergebnissen.
Der folgende Code beinhaltet nur das FNC1 Zeichen mit dem Codewortwert (DataMatrix) 232
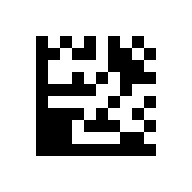
Der nächste Code ist mit dem ASCII Zeichen 232 kodiert. Das sieht dann anders aus und erfüllt die gewünschte Funktion nicht.