Code 128
Der Code 128 ist eine Codeart mit vier unterschiedlichen Strich- und Lückenbreiten. Es gibt 103 verschiedene Codewörter und dazu kommen 3 unterschiedliche Startzeichen und zusätzlich ein Stoppzeichen. Eine Besonderheit des Code 128 ist die Möglichkeit die Codewörter zum Dekodieren unterschiedlich zu interpretieren. Damit können mehr als 103 verschiedene Zeichen kodiert werden. Für rein numerische Kodierungen gibt es eine Möglichkeit in ein Codewort 2 Ziffern zu packen. Die Codewörter mit den Nummern von 00 - 99 kodieren damit das jeweilige Ziffernpärchen. Der Vorteil ist der Platzgewinn. Für 10 Ziffern werden nur 5 Codewörter und nicht 10 Codewörter benötigt.
![]()
Diese Code128 Grafik ist so gestaltet, dass ein Modul genau vier Bildpixel groß ist. Damit ist ein pixelgenaues Codebild entstanden, welches jederzeit ganzzahlig größer skaliert werden kann ohne an Genauigkeit zu verlieren.
Die Breite der Ruhezone mit jeweils 10 Modulen ist durch den oben und unten stehenden waagerechten grünen Strich angezeigt. Die Datenzeichen sowie das Start- und Stoppzeichen sind durch alternierende, waagerechte Striche über den Code markiert worden. Jeder schwarze bzw. rote waagerechte Strich markiert genau ein Codewort. Die Breite eines Codewortes wird als P-Wert bezeichnet. Die beiden blauen Striche markieren das Start- und Stoppzeichen.
Die unterschiedliche Interpretationsmöglichkeit der Codewörter wird Zeichensatz genannt. Es gibt den Zeichensatz A, Zeichensatz B und den Zeichensatz C. Der Zeichensatz C ist für die rein numerische Ziffernpärchenkodierung vorgesehen. Die drei Startzeichen heißen Startzeichen A, B und C. Diese Startzeichen weisen den Dekoder im Scanner an, die Codewörter im Zeichensatz A, B oder C zu interpretieren. Zusätzlich gibt es Umschaltzeichen die nach belieben im Code benutzt werden können. Diese Umschaltzeichen erlauben es innerhalb des Codes den Zeichensatz zu wechseln.
Moderne Coderstellungsoftware optimiert die Zeichensatzauswahl und den Zeichensatzwechsel im Code so, dass der generierte Code die kleinstmögliche Anzahl an Codewörtern benutzt. Eine Angabe, dass ein bestimmter Zeichensatz zu benutzen ist daher nicht notwendig. Für den Dekoder ist Zeichensatzwahl transparent. Er liefert der Anwendung immer die richtigen Zeichen unabhängig davon welcher Zeichensatz im Code benutzt wurde.
Ein Codewort des Code128 umfasst immer 3 Striche und 3 Lücken. Das Codewort beginnt mit einem Strich und hört mit einer Lücke auf. Das folgende Codewort beginnt wieder mit einem Strich. Eine Trennlücke wir bei dem Code 39 ist daher bei dem Code 128 nicht erforderlich.
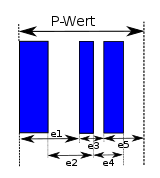
Ein Codewort besteht immer aus 11 Modulen (die 11 Module sind wieder ein P-Wert). Das Stoppzeichen umfasst 13 Module.
Links und rechts des Strichcodes muss ein heller Bereich frei bleiben. Man bezeichnet diesen hellen Bereich als Ruhezone oder Hellfeld. Die Mindestbreite des Hellfeldes ist eine relative Angabe in Bezug auf die Idealbreite eines dünnen Striches (Modulbreite). Mindestens 10 x der Breite des schmalen Striches muss links wie auch rechts des Codes freibleiben. In der Planungs- bzw. Designphase sollte immer eine Plustoleranz für die Ruhezonen eingeplant werden, damit Druck- und Positionstoleranzen das Hellfeld nicht zu schmal werden lassen.
Der Code 128 muss eine Prüfziffer beinhalten. Diese wird in dem Modulo 103 Verfahren berechnet.
Der Code 128 ist in einer ISO/IEC Norm normiert: ISO/IEC 15417. Die Zeichensatztabelle ist als Datei abrufbar.
Zeichensatztabelle Code 128 PDF-Format
Zeichensatztabelle Code 128 LibreOffice ODT Format
GS1-128 ist eine Anwendung des Code 128. Der Code 128 wird als Datenträger für die Datenstrukturen nach Vorgaben der privatwirtschaftlich aufgestellten GS1 Organisation benutzt. Als Erkennungsmerkmal muss in diesem Fall das Code 128 Spezialzeichen FNC1 immer als erstes Zeichen im Code erscheinen. Ein häufiger Fehler bei der Nutzung des Code 128 mit den Datenstrukturen der GS1 Organisation ist das Weglassen des Barcodezeichens FNC1.
Die Anfälligkeit gegen zu kurzes Lesen ist deutlich geringer als bei dem 2/5i Code. Dies begründet sich dadurch dass das Startzeichen genauso aufgebaut ist wie ein Datenzeichen und keine Teilmenge eines Datenzeichens ist. Zudem ist das Stoppzeichen mit 13 Modulen länger als die Datenzeichen und die Startzeichen. Das zu kurze Lesen erfordert daher beim Code 128 eine komplette Fehlinterpretation von Datenzeichen.
Im Vergleich zum Code 39 benötigt der Code128 wenig Platz. Im Zeichensatz C wird ab etwa 10 Ziffern der Platzbedarf sogar geringer als beim Code 2/5 interleaved.